Swoole 学习:协程、线程、IO多路复用、PHP多进程。
起步
回顾自己学的操作系统原理,线程分为系统级线程和用户级线程(线程是调度单位、进程是资源分配单位)
系统级:调度由操作系统控制,线程之间的切换是系统层面;
用户级:程序内的类似老大一样的程序控制着所有的线程,切换是在程序内完成,相比系统级的线程切换更快,基本不消耗资源;
不同在哪呢?系统级线程的分配的时间片(由操作系统分配的运行时间)是1比1的,创建10个就是10个量级。用户级线程则是共享着所属进程的时间片,创建10个相当于1/10。
Swoole安装
1. https://github.com/swoole/swoole-src/releases,下载源代码;
2.上传、解压、cd打开目录;
3. 运行php安装目录下的phpize文件,这时候会在extension目录下生成相应的configure文件。
4. ./configure --with-php-config=/usr/local/php/bin/php-config 运行配置,如果你的服务器上只是装了一个版本的php则不需要添加--with-php-config 。后面的参数只是为了告诉phpize要建立基于哪个版本的扩展。(--enable-openssl,指定打开ssl支持),
5.make && make install 编译模块,编译好模块之后,需要让php启用它。
6. 编译安装到系统成功后,需要在 php.ini 中加入一行 extension=swoole.so 来启用 Swoole 扩展
7.php --ri swoole ,用于查看指定拓展的相关信息。可通过该命令查看swoole的编译选项。
IO多路复用
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。
这样在处理1000个连接时,只需要1个线程监控就绪状态,对就绪的每个连接开一个线程处理就可以了,这样需要的线程数大大减少,减少了内存开销和上下文切换的CPU开销。这个好理解。
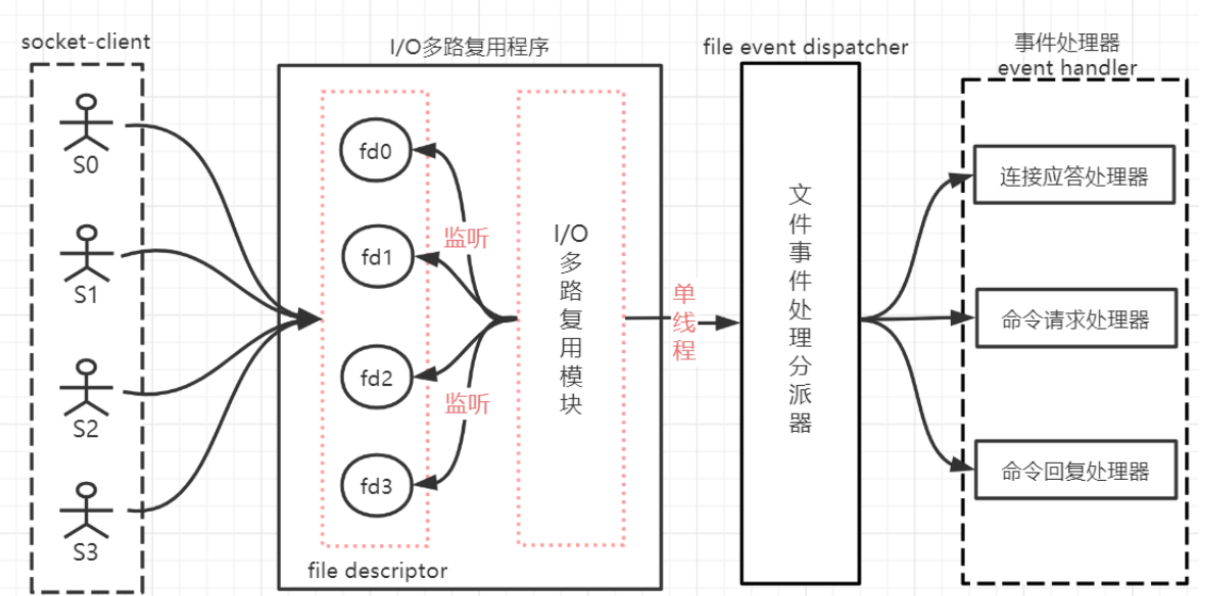
1.IO模型
- 同步阻塞IO(Blocking IO):在进行IO数据请求时,如果数据没有准备好,就要一直阻塞等待数据准备好。
- 同步非阻塞IO(Non-blocking IO):非阻塞IO就是在请求获取数据的时候,不管是否准备好数据,都会直接有返回。但是为了获取到数据,一般还是会采用轮询或者其他方式去询问数据准备情况。直到数据读取完毕。
- 多路复用IO(IO Multiplexing):即经典的Reactor设计模式,用一个进/线程委托去轮询多个IO请求。当某一个IO已经准备好数据,就会通知相应进程来处理。
- 异步IO(Asynchronous IO):异步IO就是在请求数据之后,系统立即返回。等到系统准备好数据并加载到进程中之后,就会发送信号通知进程来进行数据处理。
PHP多进程
fork之后,操作系统会复制一个与父进程完全相同的子进程,虽说是父子关系,但是在操作系统看来,他们更像兄弟关系,这2个进程共享代码空间, 但是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也完全相同,但只有一点不同,如果fork成功,子进程中fork的返回值是0, 父进程中fork的返回值是子进程的进程号,如果fork失败,父进程会返回错误。 可以这样想象,2个进程一直同时运行,而且步调一致,在fork之后,他们分别作不同的工作,也就是分岔了,这也是fork为什么叫fork的原因。 至于哪一个进程最先运行,这与操作系统平台的调度算法有关,而且这个问题在实际应用中并不重要,如果需要父子进程协同运作,可以通过控制语法结构的办法解决。
如果一个任务被分解成多个进程执行,就会减少整体的耗时。
比如有一个比较大的数据文件要处理,这个文件由很多行组成。如果单进程执行要处理的任务,量很大时要耗时比较久。这时可以考虑多进程。
来看一道面试题,有一个1000万个元素的int数组,需要求和,平均分到4个进程处理,每个进程处理一部分,再将结果统计出来,代码如下
上诉答案中,是把数组分为4个子数组分别用4个子进程去处理了,但是没有办法把所计算的结果相加,因为进程都是独立完成任务的,没有办法共享同一个(内存)变量,下面将引进消息队列来解决进程通信的问题
原文:https://blog.csdn.net/kingandwede136/article/details/85047116
1.进程通信
- 管道通信,分为有名管道,无名管道等,可自行搜索了解详细
- 消息队列通信,使用linux消息队列,通过sysvmsg扩展,可查看:http://www.php20.cn/article/137
- 进程信号通信,可查看:http://www.php20.cn/article/134
- 共享内存通信,映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
- 套接字通信
- 第三方通信,使用文件操作,mysql,redis等方法也可实现通信
2.进程信号
信号(Signals )是Unix系统中使用的最古老的进程间通信的方法之一。操作系统通过信号来通知进程系统中发生了某种预先规定好的事件(一组事件中的一个),它也是用户进程之间通信和同步的一种原始机制。一个键盘中断或者一个错误条件(比如进程试图访问它的虚拟内存中不存在的位置等)都有可能产生一个信号。Shell也使用信号向它的子进程发送作业控制信号。
信号是在Unix System V中首先引入的,它实现了15种信号,但很不可靠。BSD4.2解决了其中的许多问题,而在BSD4.3中进一步加强和改善了信号机制。但两者的接口不完全兼容。在Posix 1003.1标准中做了一些强行规定,它定义了一个标准的信号接口,但没有规定接口的实现。目前几乎所有的Unix变种都提供了和Posix标准兼容的信号实现机制。
3.僵尸进程
僵尸进程是当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程。
在unix进程管理中,如果你新开的子进程运行结束,父进程将会收到一个SIGCHLD信号,子进程成为僵尸进程(保存了进程的状态等信息),等待父进程的处理,如果父进程一直不处理,该进程将会一直存在,占用系统进程表项,如果僵尸进程过多,导致系统没有可用的进程表项,于是再也无法运行其他的程序
4.孤儿进程
孤儿进程指的是在其父进程执行完成或被终止后仍继续运行的一类进程。这些孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
孤儿进程没有任何危害,只是需要注意自己的代码逻辑即可.
5.守护进程
守护进程(daemon)是一类在后台运行的特殊进程,用于执行特定的系统任务。很多守护进程在系统引导的时候启动,并且一直运行直到系统关闭。另一些只在需要的时候才启动,完成任务后就自动结束。
用户使守护进程独立于所有终端是因为,在守护进程从一个终端启动的情况下,这同一个终端可能被其他的用户使用。例如,用户从一个终端启动守护进程后退出,然后另外一个人也登录到这个终端。用户不希望后者在使用该终端的过程中,接收到守护进程的任何错误信息。同样,由终端键人的任何信号(例如中断信号)也不应该影响先前在该终端启动的任何守护进程的运行。虽然让服务器后台运行很容易(只要shell命令行以&结尾即可),但用户还应该做些工作,让程序本身能够自动进入后台,且不依赖于任何终端。
Swoole的相关进程

1.Master
Master 进程是一个多线程进程
2.Reactor 线程
- Reactor 线程是在 Master 进程中创建的线程
- 负责维护客户端 TCP 连接、处理网络 IO、处理协议、收发数据
- 不执行任何 PHP 代码
- 将 TCP 客户端发来的数据缓冲、拼接、拆分成完整的一个请求数据包
3.Worker 进程
- 接受由 Reactor 线程投递的请求数据包,并执行 PHP 回调函数处理数据
- 生成响应数据并发给 Reactor 线程,由 Reactor 线程发送给 TCP 客户端
- 可以是异步非阻塞模式,也可以是同步阻塞模式
- Worker 以多进程的方式运行
4.TaskWorker 进程
- 接受由 Worker 进程通过 SwooleServer->task/taskwait/taskCo/taskWaitMulti 方法投递的任务
- 处理任务,并将结果数据返回(使用 SwooleServer->finish)给 Worker 进程
- 完全是同步阻塞模式
- TaskWorker 以多进程的方式运行
5.Manager 进程
- 负责创建 / 回收 worker/task 进程 。